|
Monster SCALE Summit 2026 (Sponsored)
Extreme Scale Engineering | Online | March 11-12
 |
Your free ticket to Monster SCALE Summit is waiting — 30+ engineering talks on data-intensive applications
Monster SCALE Summit is a virtual conference that’s all about extreme-scale engineering and data-intensive applications. Engineers from Discord, Disney, LinkedIn, Pinterest, Rivian, American Express, Google, ScyllaDB, and more will be sharing 30+ talks on topics like:
Distributed databases
Streaming and real-time processing
Intriguing system designs
Massive scaling challenge
Don’t miss this chance to connect with 20K of your peers designing, implementing, and optimizing data-intensive applications – for free, from anywhere.
Register now to save your seat, and become eligible for an early bird swag pack!
Disclaimer: The details in this post have been derived from the details shared online by the Netflix Engineering Team. All credit for the technical details goes to the Netflix Engineering Team. The links to the original articles and sources are present in the references section at the end of the post. We’ve attempted to analyze the details and provide our input about them. If you find any inaccuracies or omissions, please leave a comment, and we will do our best to fix them.
Netflix processes an enormous amount of data every second. Each time a user plays a show, rates a movie, or receives a recommendation, multiple databases and microservices work together behind the scenes. This functionality is supported using hundreds of independent systems that must stay consistent with each other. When something goes wrong in one system, it can quickly create a ripple effect across the platform.
Netflix’s engineering team faced several recurring issues that threatened the reliability of their data. Some of these included accidental data corruption after schema changes, inconsistent updates between storage systems such as Apache Cassandra and Elasticsearch, and message delivery failures during transient outages. At times, bulk operations like large delete jobs even caused key-value database nodes to run out of memory. On top of that, some databases lacked built-in replication, which meant that regional failures could lead to permanent data loss.
Each engineering team tried to handle these issues differently. One team would build custom retry systems, another would design its own backup strategy, and yet another would use Kafka directly for message delivery. While these solutions worked individually, they created complexity and inconsistent guarantees across Netflix’s ecosystem. Over time, this patchwork approach increased maintenance costs and made debugging more difficult.
To fix this, Netflix built a Write-Ahead Log system to act as a single, resilient foundation for data reliability. The WAL standardizes how data changes are recorded, stored, and replayed across services. In simple terms, it captures every change before it is applied to the database, so that even if something fails midway, no information is lost.
In this article, we will look at how Netflix built this WAL and the challenges it faced.
What is a Write-Ahead Log?
At its core, a Write-Ahead Log is a simple but powerful idea. It is a system that keeps a record of every change made to data before those changes are applied to the actual database. You can think of it like keeping a journal of all the actions you plan to take. Even if something goes wrong during the process, you still have that journal to remind you exactly what you were doing, so you can pick up right where you left off.
In practical terms, when an application wants to update or delete information in a database, it first writes that intention to the WAL. Only after the entry has been safely recorded does the database proceed with the operation. This means that if a server crashes or a network connection drops, Netflix can replay the operations from the WAL and restore everything to the correct state. Nothing is lost, and the data remains consistent across systems.
Netflix’s version of WAL is not tied to a single database or service.
It is distributed, meaning it runs across multiple servers to handle massive volumes of data. It is also pluggable, allowing it to connect easily to various technologies, such as Kafka, Amazon SQS, Apache Cassandra, and EVCache. This flexibility allowed the Netflix engineering team to use the same reliability framework for different types of workloads, whether it’s storing cached video metadata, user preferences, or system logs.
See the diagram below:
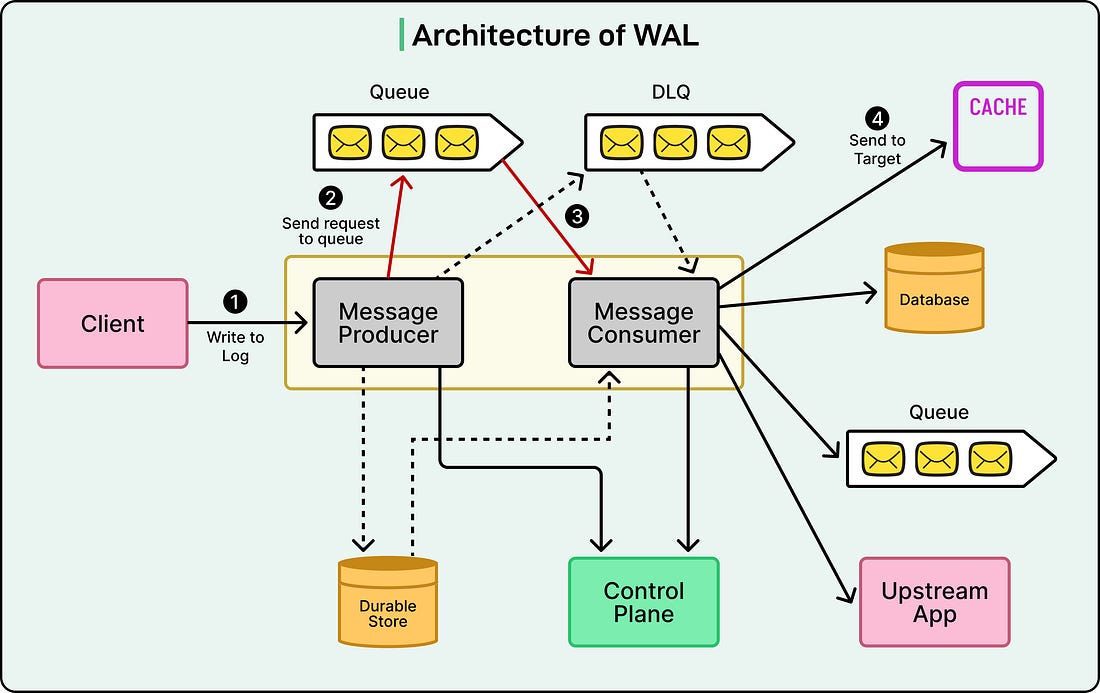 |
The WAL provides several key benefits that make Netflix’s data platform more resilient:
Durability: Every change is logged first, so even if a database goes offline, no data is permanently lost.
Retry and Delay Support: If a message fails to process due to an outage or network issue, the WAL can automatically retry it later, with custom delays.
Cross-Region Replication: Data can be copied across regions, ensuring the same information exists in multiple data centers for disaster recovery.
Multi-Partition Consistency: For complex updates involving multiple tables or partitions, WAL ensures that all changes are coordinated and eventually consistent.
The WAL API
Netflix’s Write-Ahead Log system provides a simple interface for the developers. Despite the complexity of what happens behind the scenes, the API that developers interact with contains only one main operation called WriteToLog.
This API acts as the entry point for any application that wants to record a change. The structure looks something like this:
rpc WriteToLog (WriteToLogRequest) returns (WriteToLogResponse);
Even though this may look technical, the idea is straightforward. A service sends a request to WAL describing what it wants to write and where that data should go. WAL then processes the request, stores it safely, and responds with information about whether the operation was successful.
The request contains four main parts:
Namespace: This identifies which logical group or application the data belongs to. Think of it as a label that helps WAL organize and isolate data from different teams or services.
Lifecycle: This specifies timing details, such as whether the message should be delayed or how long WAL should keep it.
Payload: This is the actual content or data being written to the log.
Target: This tells WAL where to send the data after it has been safely recorded, such as a Kafka topic, a database, or a cache.
The response from WAL is equally simple:
Durable: Indicates whether the request was successfully stored and made reliable.