|
 |
👋 Hi, this is Gergely with a subscriber-only issue of the Pragmatic Engineer Newsletter. In every issue, I cover challenges at Big Tech and startups through the lens of engineering managers and senior engineers. If you’ve been forwarded this email, you can subscribe here.
A pragmatic guide to LLM evals for devs
Evals are a new toolset for any and all AI engineers – and software engineers should also know about them. Move from guesswork to a systematic engineering process for improving AI quality.
One word that keeps cropping up when I talk with software engineers who build large language model (LLM)-based solutions is “evals”. They use evaluations to verify that LLM solutions work well enough because LLMs are non-deterministic, meaning there’s no guarantee they’ll provide the same answer to the same question twice. This makes it more complicated to verify that things work according to spec than it does with other software, for which automated tests are available.
Evals feel like they are becoming a core part of the AI engineering toolset. And because they are also becoming part of CI/CD pipelines, we, software engineers, should understand them better — especially because we might need to use them sooner rather than later! So, what do good evals look like, and how should this non-deterministic-testing space be approached?
For directions, I turned to an expert on the topic, Hamel Husain. He’s worked as a Machine Learning engineer at companies including Airbnb and GitHub, and teaches the online course AI Evals For Engineers & PMs — the upcoming cohort starts in January. Hamel is currently writing a book, Evals for AI Engineers, to be published by O’Reilly next year.
In today’s issue, we cover:
Vibe-check development trap. An agent appears to work well, but as soon as it is modified, it can’t be established that it’s working correctly.
Core workflow: error analysis. Error analysis has been a key part of machine learning for decades and is useful for building LLM applications.
Building evals: the right tools for the job. Use code-based evals for deterministic failures, and an LLM-as-judge for subjective cases.
Building an LLM-as-judge. Avoid your LLM judge memorizing answers by partitioning your data and measuring how well the judge generalizes to unfamiliar data.
Align the judge, keep trust. The LLM judge’s expertise needs to be validated against human expertise. Consider metrics like True Positive Rate (TPR) and True Negative Rate (TNR).
Evals in practice: from CI/CD to production monitoring. Use evals in the CI/CD pipeline, but use production data to continuously validate that they work as expected, too.
Flywheel of improvement. Analyze → measure → Improve → automate → start again
The bottom of this article could be cut off in some email clients. Read the full article uninterrupted, online.
With that, it’s over to Hamel:
1. Vibe-check development trap
Organizations are embedding LLMs into applications from customer service to content creation. Yet, unlike traditional software, LLM pipelines don’t produce deterministic outputs; their responses are often subjective and context-dependent. A response might be factually accurate but have the wrong tone, or sound persuasive while being completely wrong. This ambiguity makes evaluation fundamentally different from conventional software testing. The core challenge is to systematically measure the quality of our AI systems and diagnose their failures.
I recently worked with NurtureBoss, an AI startup building a leasing assistant for apartment property managers. The assistant helps with tour scheduling, answers routine tenant questions, and inbound sales. Here is a screenshot of how the product appears to customers:
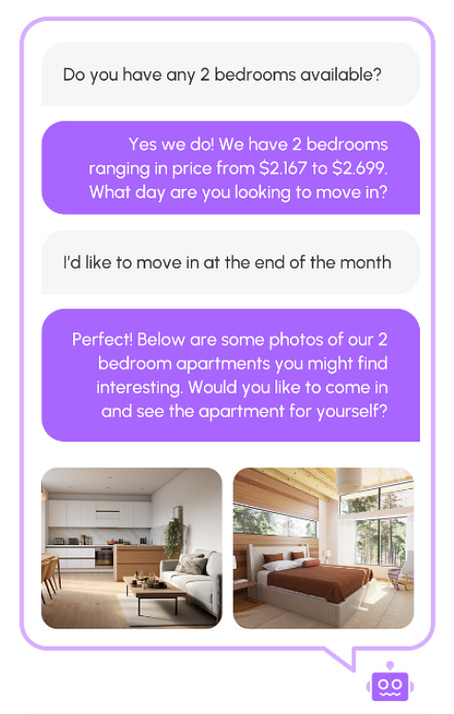 |
They had built a sophisticated agent, but the development process felt like guesswork: they’d change a prompt, test a few inputs, and if it “looked good to me” (LGTM), they’d ship it. This is the “vibes-based development” trap, and it’s where many AI projects go off the rails.
To understand why this happens, it helps to think of LLM development as bridging three fundamental gaps, or “gulfs”:
Gulf of Comprehension: The gap between a developer and a true understanding of their data and the model’s behavior at scale. It’s impossible to manually read every user query and inspect every AI response to grasp the subtle ways a system might fail.
Gulf of Specification: The gap between what we want the LLM to do, and what our prompts actually instruct it to do. LLMs cannot read our minds; an underspecified prompt forces them to guess our intent, leading to inconsistent outputs.
Gulf of Generalization: The gap between a well-written prompt and the model’s ability to apply those instructions reliably across all possible inputs. Even with perfect instructions, a model can still fail on new or unusual data.