|
👋 Goodbye low test coverage and slow QA cycles (Sponsored)
 |
Bugs sneak out when less than 80% of user flows are tested before shipping. However, getting that kind of coverage (and staying there) is hard and pricey for any team.
QA Wolf’s AI-native solution provides high-volume, high-speed test coverage for web and mobile apps, reducing your organization’s QA cycle to minutes.
They can get you:
80% automated E2E test coverage in weeks—not years
24-hour maintenance and on-demand test creation
Zero flakes, guaranteed
The benefit? No more manual E2E testing. No more slow QA cycles. No more bugs reaching production.
With QA Wolf, Drata’s team of engineers achieved 4x more test cases and 86% faster QA cycles.
⭐ Rated 4.8/5 on G2
Disclaimer: The details in this post have been derived from the details shared online by the Meta Engineering Team. All credit for the technical details goes to the Meta Engineering Team. The links to the original articles and sources are present in the references section at the end of the post. We’ve attempted to analyze the details and provide our input about them. If you find any inaccuracies or omissions, please leave a comment, and we will do our best to fix them.
Meta has one of the largest data warehouses in the world, supporting analytics, machine learning, and AI workloads across many teams. Every business decision, experiment, and product improvement relies on quick, secure access to this data.
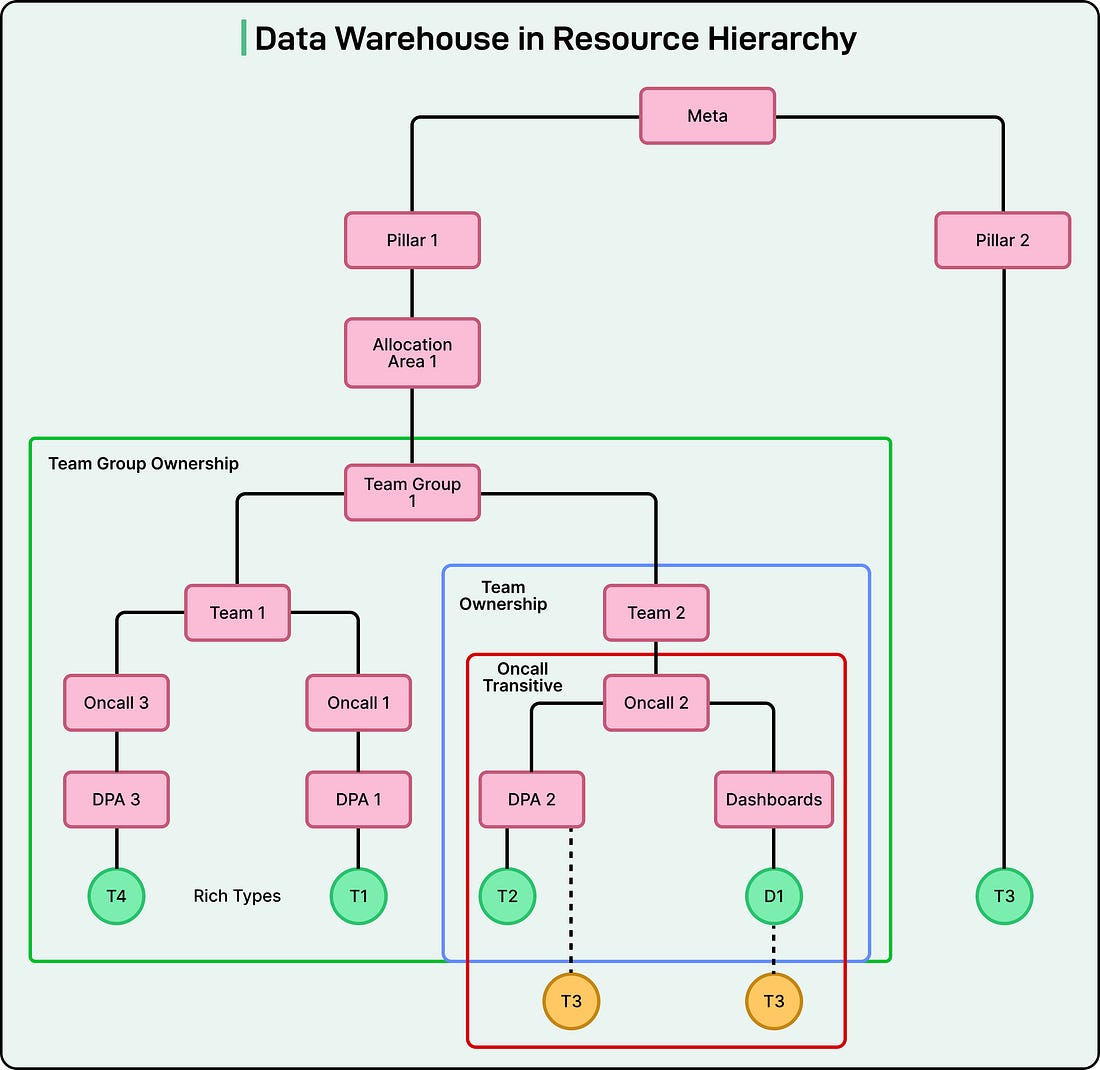
To organize such a vast system, Meta built its data warehouse as a hierarchy. At the top are teams and organizations, followed by datasets, tables, and finally dashboards that visualize insights. Each level connects to the next, forming a structure where every piece of data can be traced back to its origin.
Access to these data assets has traditionally been managed through role-based access control (RBAC). This means access permissions are granted based on job roles. A marketing analyst, for example, can view marketing performance data, while an infrastructure engineer can view server performance logs. When someone needed additional data, they would manually request it from the data owner, who would approve or deny access based on company policies.
This manual process worked well in the early stages. However, as Meta’s operations and AI systems expanded, this model began to strain under its own weight. Managing who could access what became a complex and time-consuming process.
Three major problems began to emerge:
The data graph became massive. Each table, dashboard, and data pipeline connects to others, forming a web of relationships. Understanding dependencies and granting permissions safely across this web became difficult.
Access decisions became slower and required multiple approvals. Different teams had to coordinate across departments to manage security.
AI systems changed how data was used. Earlier, each team mainly worked within its own data domain. Now, AI models often need to analyze data from multiple domains at once. The traditional human-managed access system could not keep up with these cross-domain patterns.
To keep innovation moving while maintaining security, Meta had to find a better way to handle the problem of data access at scale. The Meta engineering team discovered that the answer lay in AI agents. These agents are intelligent software systems capable of understanding requests, evaluating risks, and making decisions autonomously within predefined boundaries
In this article, we look at how Meta redesigned their data warehouse architecture to work with both humans and agents.
 |
The Agentic Solution: Two-Agent Architecture
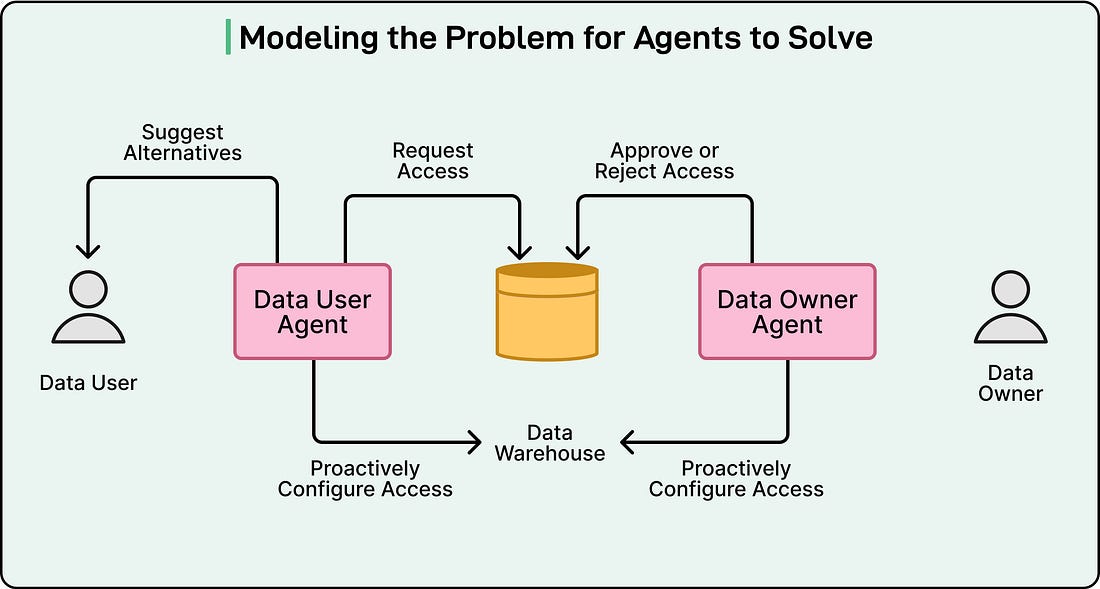
To overcome the growing complexity of data access, the Meta engineering team developed what they call a multi-agent system.
In simple terms, it is a setup where different AI agents work together, each handling specific parts of the data-access workflow. This design allows Meta to make data access both faster and safer by letting agents take over the repetitive and procedural tasks that humans once did manually.
At the heart of this system are two key types of agents that interact with each other:
Data-user agents, which act on behalf of employees or systems that need access to data.
Data-owner agents, which act on behalf of the people or teams responsible for managing and protecting data.
See the diagram below:
 |
Data-User Agent
The data-user agent is not one single program. Instead, it is a group of smaller, specialized agents that work together. These sub-agents are coordinated by a triage layer, which acts like a manager that decides which sub-agent should handle each part of the task.
See the diagram below: