|
Build product instead of babysitting prod. (Sponsored)
 |
Engineering teams at Coinbase, MSCI, and Zscaler have at least one thing in common: they use Resolve AI’s AI SRE to make MTTR 5x faster and increase dev productivity by up to 75%.
When it comes to production issues, the numbers hurt: 54% of significant outages exceed $100,000 lost. Downtime cost the Global 2000 ~$400 billion annually.
It’s why eng teams leverage our AI SRE to correlate code, infrastructure, and telemetry, and provide real-time root cause analysis, prescriptive remediation, and continuous learning.
Time to try an AI SRE? This guide covers:
The ROI of an AI SRE
Whether you should build or buy
How to assess AI SRE solutions
Recently, a twenty four year old researcher named Matt Deitke received a two hundred and fifty million dollar offer from Meta’s Superintelligence Lab. While the exact details behind this offer are not public, many people believe his work on multimodal models, especially the paper called Molmo, played a major role. Molmo stands out because it shows how to build a strong vision language model from the ground up without relying on any closed proprietary systems. This is rare in a landscape where most open models indirectly depend on private APIs for training data.
This article explains what Molmo is, why it matters, and how it solves a long-standing problem in vision language modeling. It also walks through the datasets, training methods, and architectural decisions that make Molmo unique.
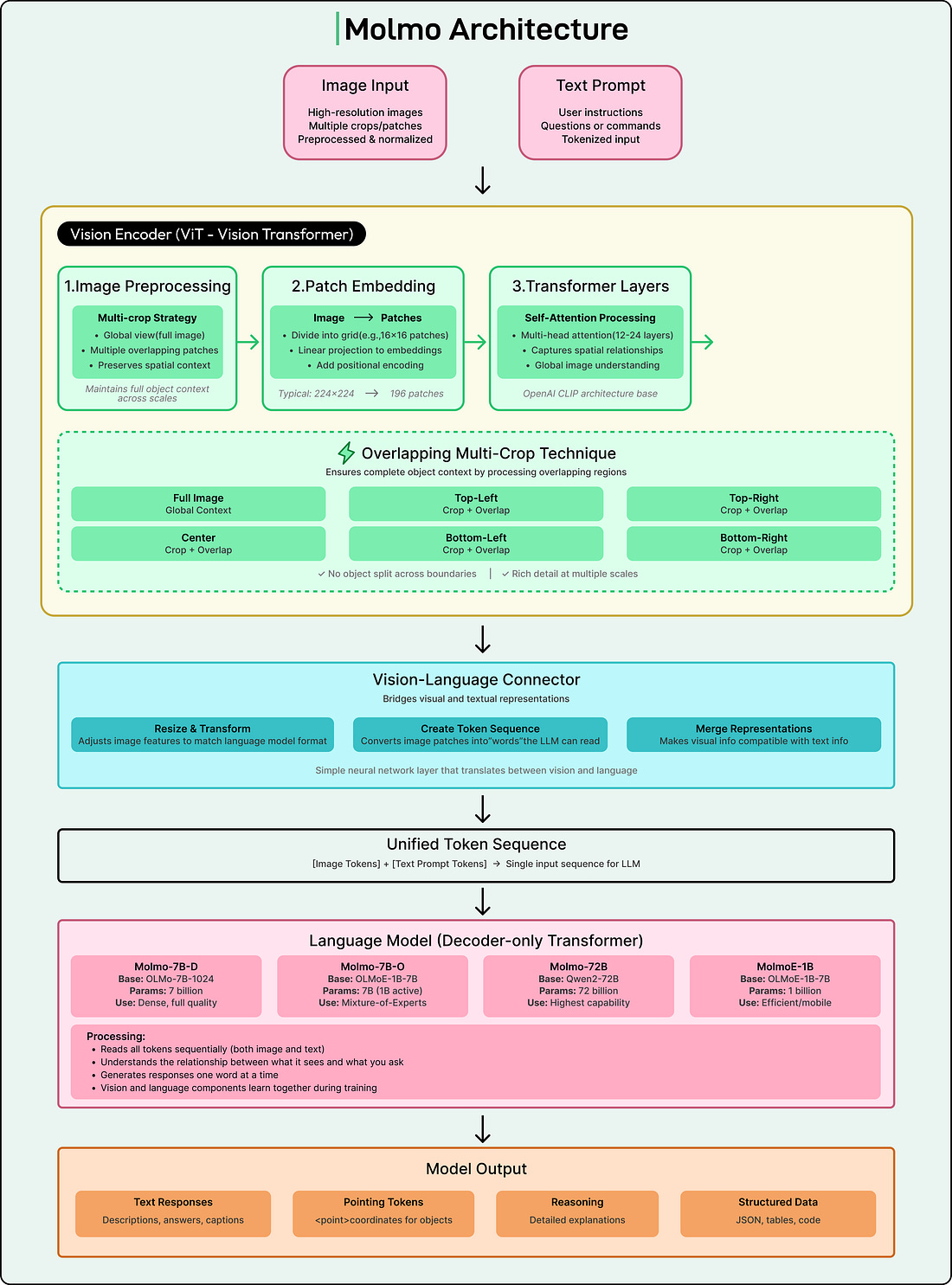 |
The Core Problem Molmo Solves
Vision language models, or VLMs, are systems like GPT-4o or Google Gemini that can understand images and text together. We can ask them to describe a picture, identify objects, answer questions about a scene, or perform reasoning that requires both visual and textual understanding.
See the diagram below:
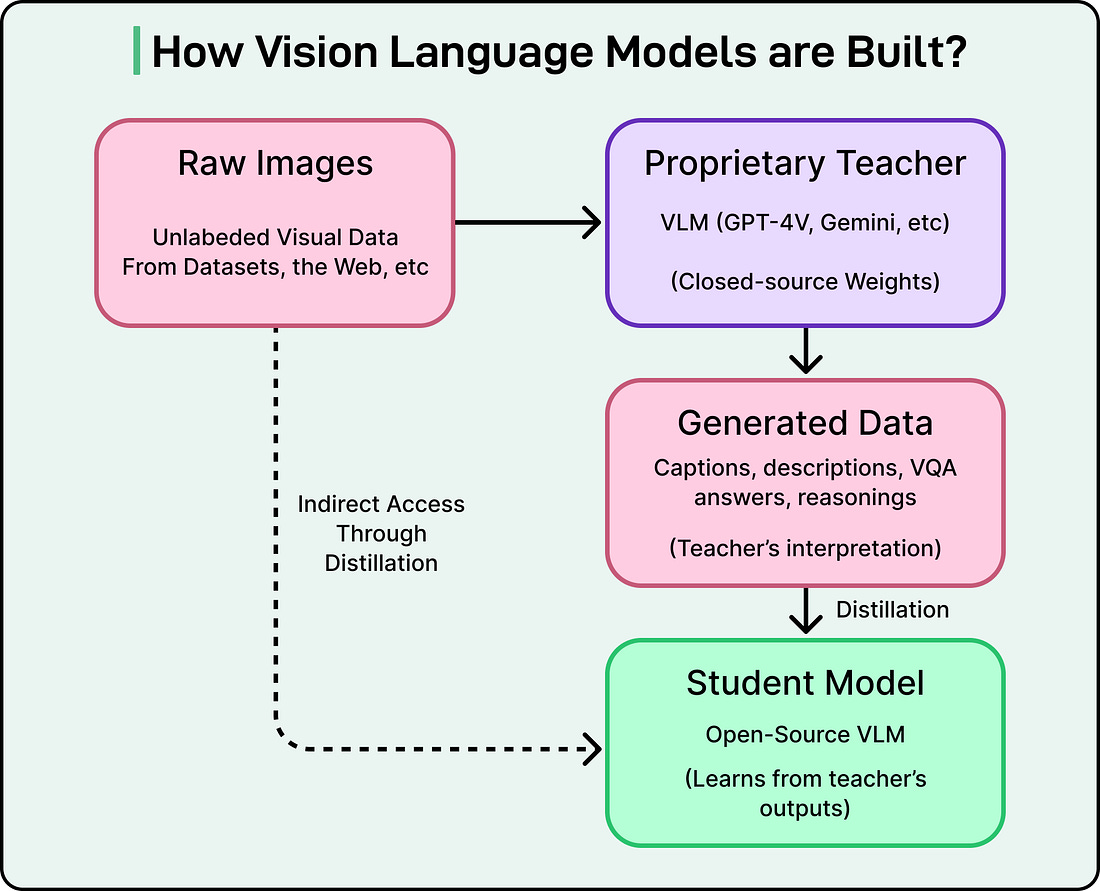 |
Many open weight VLMs exist today, but most of them rely on a training approach called distillation. In distillation, a smaller student model learns by imitating the outputs of a larger teacher model.
The general process looks like this:
The teacher sees an image.
It produces an output, such as “A black cat sitting on a red couch.”
Researchers collect these outputs.
The student is trained to reproduce the teacher’s answers.
Developers may generate millions of captions using a proprietary model like GPT 4 Vision, then use those captions as training data for an “open” model. This approach is fast and inexpensive because it avoids large-scale human labeling. However, it creates several serious problems.
The first problem is that the result is not truly open. If the student model was trained on labels from a private API, it cannot be recreated without that API. This creates permanent dependence.
The second problem is that the community does not learn how to build stronger models. Instead, it learns how to copy a closed model’s behavior. The foundational knowledge stays locked away.
The third problem is that performance becomes limited. A student model rarely surpasses its teacher, so the model inherits the teacher’s strengths and weaknesses.
This is similar to copying a classmate’s homework. It might work for the moment, but we do not gain the underlying skill, and if the classmate stops helping, we are stuck.
Molmo was designed to break this cycle. It is trained entirely on datasets that do not rely on existing VLMs. To make this possible, the authors also created PixMo, a suite of human-built datasets that form the foundation for Molmo’s training.
The PixMo Datasets
PixMo is a collection of seven datasets, all created without using any other vision language model. The goal of PixMo is to provide high-quality, VLM-free data that allows Molmo to be trained from scratch.
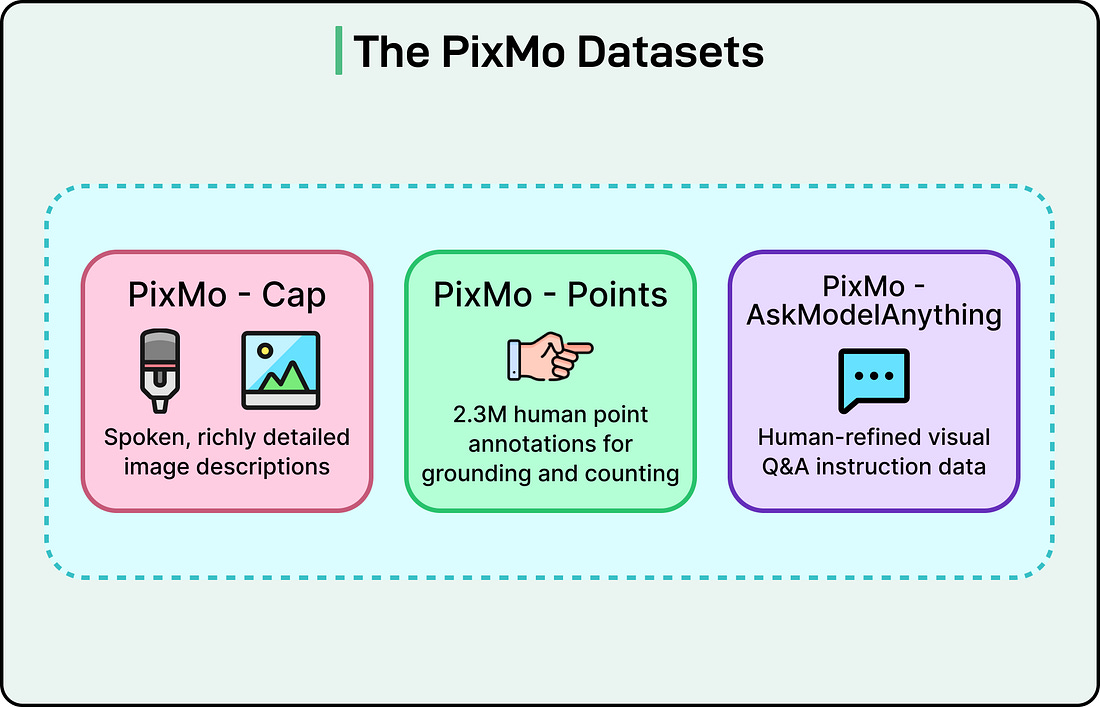 |
There are three main components of PixMo datasets: