|
The AI notepad for people in back-to-back meetings
 |
Most AI note-takers just transcribe what was said and send you a summary after the call.
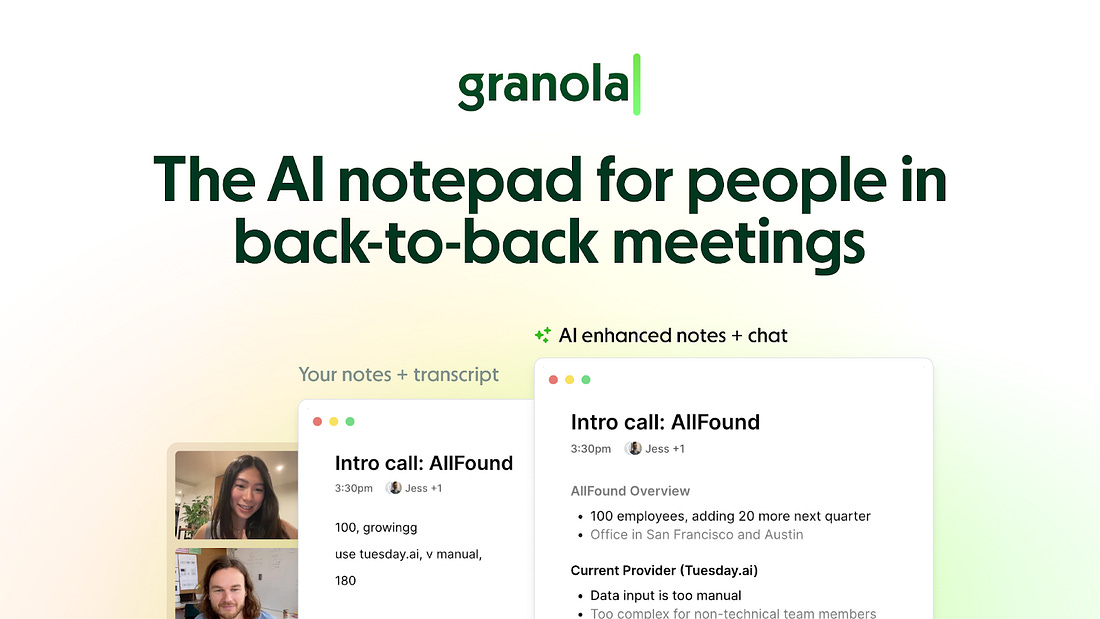
Granola is an AI notepad. And that difference matters.
You start with a clean, simple notepad. You jot down what matters to you and, in the background, Granola transcribes the meeting.
When the meeting ends, Granola uses your notes to generate clearer summaries, action items, and next steps, all from your point of view.
Then comes the powerful part: you can chat with your notes. Use Recipes (pre-made prompts) to write follow-up emails, pull out decisions, prep for your next meeting, or turn conversations into real work in seconds.
Think of it as a super-smart notes app that actually understands your meetings.
Free 1 month with the code SCOOP
Rather than converging on a single dominant architecture, the field of multimodal AI is witnessing a period of intense architectural experimentation along three distinct and fundamentally different trajectories.
Switched systems pair specialized LLMs with diffusion models, LLM-only approaches attempt to unify all modalities through token-based transformers, and diffusion-only models propose a probabilistic framework for both text and vision. None is obviously superior. Each represents a different philosophy about the nature of multimodal understanding and generation, with distinct engineering tradeoffs, training stability profiles, and performance characteristics.
The real frontier is not moving toward one pattern but toward adaptive hybridization—architectures that dynamically select computational patterns based on task requirements, data constraints, and deployment contexts.
Architecture Overview and Data Flows
The three patterns organize computation fundamentally differently. Switched systems maintain modular separation with sequential invocation. LLM-only approaches attempt early fusion through a unified token space. Diffusion-only models propose probabilistic denoising as the unifying principle.
Performance Tradeoffs Across Dimensions
 |
The comparative analysis reveals no universal winner. Understanding tasks favor LLM-only (+5-7% on MMMU), generation quality favors diffusion-based approaches (FID 8-9 vs. 15-20), and inference speed favors diffusion with configurable quality tradeoffs (1.92x faster with higher caption quality than autoregressive).
Technical Capability Matrix: Strengths and Weaknesses
 |
Examining eight critical dimensions reveals each architecture’s specialization:
Switched systems excel at modularity and training stability but suffer from latency multiplication
LLM-only achieves excellent reasoning and understanding but generation quality lags
Diffusion-only delivers state-of-the-art generation and parallel decoding but reasoning depth remains underdeveloped
The Frontier Is Fragmenting, Not Converging
1. Fundamental Capability Split: Understanding and generation appear to require different computational mechanisms. Autoregressive sequential reasoning benefits understanding; iterative refinement benefits generation. No single approach optimizes both equally.
2. Hybrid Approaches Are Emerging as the Frontier: Show-o (adaptive routing between autoregressive and diffusion), Janus (separate encoders for understanding and generation), and UniMoD (task-aware token pruning) represent the meta-level insight: rather than choosing one pattern, intelligently combine all three.
3. Speed-Quality Tradeoff Is a Unique Diffusion Advantage: LaViDa demonstrates 1.92x speedup with better caption quality than autoregressive baselines. Diffusion’s ability to trade off steps for quality is unmatched by autoregressive approaches.
4. Training Stability and Reproducibility Favor Switched Systems: Production deployment data shows switched systems have fewer failure modes. LLM-only approaches report training instability; diffusion-only is stable but represents new infrastructure.