|
 |
Why Your AI Agents Need Engineering Instead of Best Practices
I remain optimistic about the impact agents will have on knowledge work. As I noted in an earlier article, fields shaped by clear rules and mature systems, including accounting and contract management, already look well suited to this kind of automation. But even if the opportunity is real, the practical reality is that AI teams are still learning how to build agents that work reliably in production. Moving from a fragile prototype to a dependable system requires more than a good prompt. It means thinking carefully about the underlying architecture. To see how these systems come together, it helps to break the stack into its main parts.
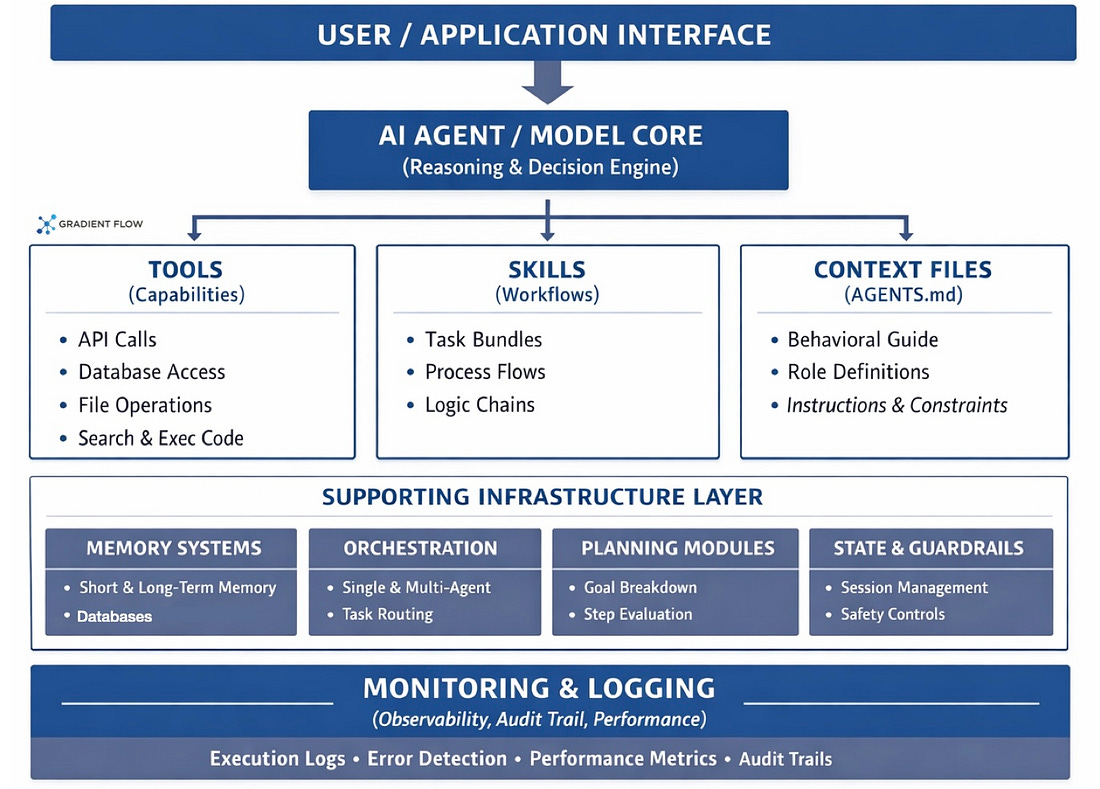
In a working AI agent system, three core components define capability and behavior.
Tools are the individual actions an agent can perform: database queries, API calls, file operations, or code execution. They are the atomic operations that enable agents to reach out and interact with external systems.
Skills operate at a higher level. They are reusable workflows that combine multiple tools with specific reasoning steps to accomplish meaningful business objectives like analyzing a contract or triaging support tickets.
Context files like AGENTS.md work differently. Rather than adding capability, they define how the agent should think and act. They specify the agent’s role, decision-making guidelines, constraints, and the reasoning patterns it applies when facing choices.
This three-layer separation is practical: it lets you mix tools into different skills, and run those skills under different behavioral frameworks, without rebuilding core logic.
Production agent systems depend on several other components that matter just as much as the tools themselves. Memory systems maintain continuity across multiple turns, allowing agents to reference past decisions and context. Orchestration frameworks determine whether one agent or multiple specialized agents should handle a task. Planning modules help break complex goals into executable sequences. State management ensures context carries across interactions. Guardrails and permissions prevent misuse and enforce organizational policy. Monitoring and logging let you see what the agent actually does, which often differs from what you expected. These pieces work together. Without memory, the agent can’t maintain context. Without orchestration, it can’t coordinate complex work. Without guardrails, it risks policy violations.
 |
Rethinking Coordination and Memory in Agent Systems
There is still a great deal of experimentation happening across all these tool categories. Orchestration is one area seeing intense activity as builders realize that early frameworks are often too rigid. Older systems force developers to map out every workflow in advance or rely on unstructured agent chats. New tools are filling this gap by offering more flexibility and control. Cord is a recent example that lets agents build their own task trees on the fly. It allows models to decide when to split work into parallel tracks or share context without needing a hardcoded plan. Emdash tackles orchestration from a workspace angle by letting developers run multiple coding agents in parallel across isolated environments. This eliminates the messy reality of juggling different terminals and waiting for a single model to finish its job.
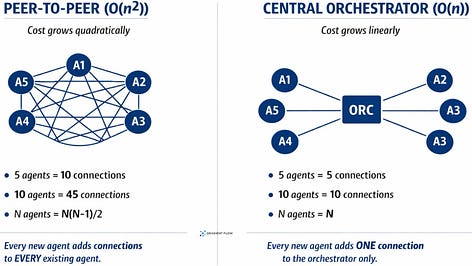
One underappreciated cost of adding agents is coordination overhead. In many-to-many designs, that overhead can rise very quickly as the number of agents grows. Centralized orchestration can reduce some of that complexity, though it introduces its own bottlenecks. More agents also means more inference costs and more opportunities for compounding errors. Recent studies suggest that adding agents helps in some settings, especially when work can be cleanly decomposed, but it can also add overhead and even reduce performance when the single-agent baseline is already strong or the task is highly sequential.
 |
Memory and context systems are also evolving to handle more than just conversational history. As I argued in an earlier piece, most current memory approaches are better at retrieving facts or preserving conversation than at helping agents repeat operational work reliably. To solve this, developers are moving toward operational skill stores or context file systems. It is less about chat history and more about procedural memory. Instead of overloading a prompt with endless documentation, these new systems save successful workflows as permanent procedures. The agent only loads the specific instructions it needs for the exact task at hand. This method turns temporary problem solving into reliable company assets while drastically cutting down on computing costs.