|
Warp: The Coding Partner You Can Trust (Sponsored)
 |
Too often, agents write code that almost works, leaving developers debugging instead of shipping. Warp changes that.
With Warp you get:
#1 coding agent: Tops benchmarks, delivering more accurate code out of the box.
Tight feedback loop: Built-in code review and editing lets devs quickly spot issues, hand-edit, or reprompt.
1-2 hours saved per day with Warp: All thanks to Warp’s 97% diff acceptance rate.
See why Warp is trusted by over 700k developers.
Disclaimer: The details in this post have been derived from the details shared online by the Perplexity Engineering Team, Vespa Engineering Team, AWS, and NVIDIA. All credit for the technical details goes to the Perplexity Engineering Team, Vespa Engineering Team, NVIDIA, and AWS. The links to the original articles and sources are present in the references section at the end of the post. We’ve attempted to analyze the details and provide our input about them. If you find any inaccuracies or omissions, please leave a comment, and we will do our best to fix them.
At its core, Perplexity AI was built on a simple but powerful idea: to change online search from a list of a few blue links into a direct “answer engine”.
The goal was to create a tool that could read through web pages for you, pull out the most important information, and give you a single, clear answer.
Think of it as a combination of a traditional search engine and a smart AI chatbot. When you ask a question, Perplexity first scours the live internet for the most current and relevant information. Then, it uses a powerful AI to read and synthesize what it found into a straightforward summary. This approach is very different from AI models that rely only on the data they were trained on, which can be months or even years out of date.
This design directly tackles two of the biggest challenges with AI chatbots:
Their inability to access current events.
Their tendency to “hallucinate” or make up facts.
By basing every answer on real, verifiable web pages and providing citations for its sources, Perplexity aims to be a more trustworthy and reliable source of information.
Interestingly, the company didn’t start with this grand vision. Their initial project was a much more technical tool for translating plain English into database queries.
However, the launch of ChatGPT in late 2022 was a turning point. The team noticed that one of the main criticisms of ChatGPT was its lack of sources. They realized their own internal prototype already solved this problem. In a decisive move, they abandoned four months of work on their original project to focus entirely on the challenge of building a true answer engine for the web. This single decision shaped the entire technical direction of the company.
Perplexity’s RAG Pipeline
The backbone of Perplexity’s service is a meticulously implemented Retrieval-Augmented Generation (RAG) pipeline. Here’s what RAG looks like on a high-level.
 |
Behind the scenes of RAG at Perplexity is a multi-step process, which is executed for nearly every query to ensure that the generated answers are both relevant and factually grounded in current information.
The pipeline can be deconstructed into five distinct stages:
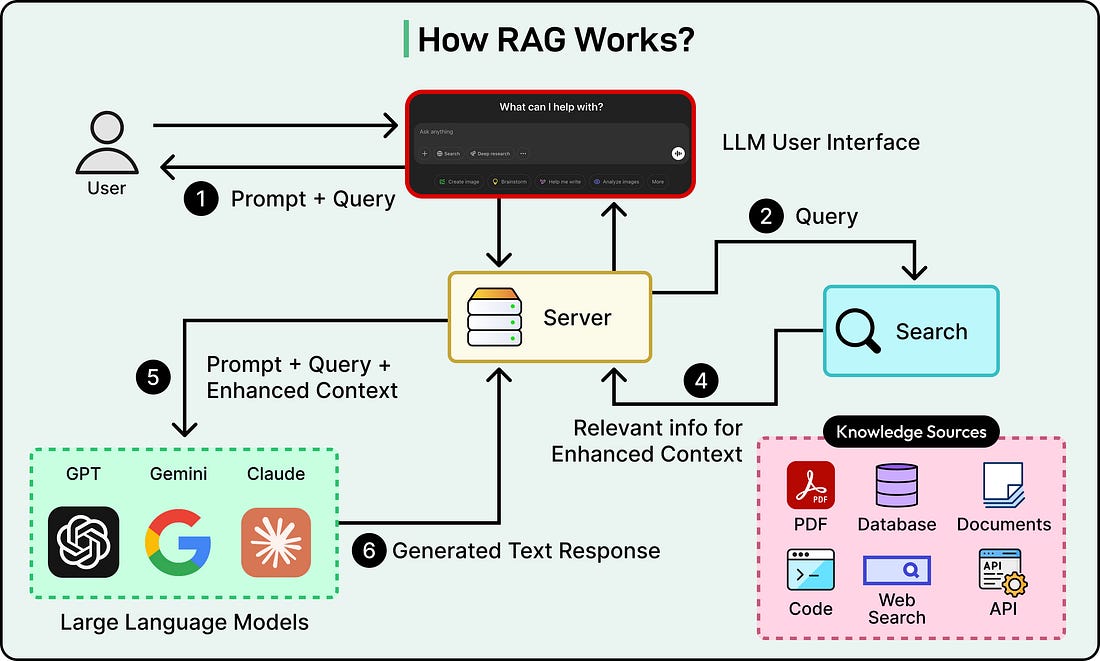
Query Intent Parsing: The process begins when a user submits a query. Instead of relying on simple keyword matching, the system first employs an LLM (which could be one of Perplexity’s own fine-tuned models or a third-party model such as GPT-4) to parse the user’s intent. This initial step moves beyond the lexical level to achieve a deeper semantic understanding of what the user is truly asking, interpreting context, nuance, and the underlying goal of the query.
Live Web Retrieval: Once the user’s intent is understood, the parsed query is dispatched to a powerful, real-time search index. This retrieval system scours the web for a set of relevant pages and documents that are likely to contain the answer. This live retrieval is a non-negotiable step in the process, ensuring that the information used for answer generation is always as fresh and up-to-date as possible.
Snippet Extraction and Contextualization: The system does not pass the full text of the retrieved web pages to the generative model. Instead, it utilizes algorithms to extract the most relevant snippets, paragraphs, or chunks of text from these sources. These concise snippets, which directly pertain to the user’s query, are then aggregated to form the “context” that will be provided to the LLM.
Synthesized Answer Generation with Citations: The curated context is then passed to the chosen generative LLM. The model’s task is to generate a natural-language, conversational response based only on the information contained within that provided context. This is a strict and defining principle of the architecture: “you are not supposed to say anything that you didn’t retrieve”. To enforce this principle and provide transparency, a crucial feature is the attachment of inline citations to the generated text. These citations link back to the source documents, allowing users to verify every piece of information and delve deeper into the source material if they choose.
Conversational Refinement: The Perplexity system is designed for dialogue, not single-shot queries. It maintains the context of the ongoing conversation, allowing users to ask follow-up questions. When a follow-up is asked, the system refines its answers through a combination of the existing conversational context and new, iterative web searches.
The diagram below shows a general view of how RAG works in principle:
 |
The Orchestration Layer
Perplexity’s core technical competency is not the development of a single, superior LLM but rather the orchestration of combining various LLMs with a high-performance search system to deliver fast, accurate, and cost-efficient answers. This is a complex challenge that needs to balance the high computational cost of LLMs with the low-latency demands of a real-time search product.
To solve this, the architecture is explicitly designed to be model-agnostic.