|
The developer toolkit for shipping AI features with confidence (Sponsored)
 |
With release cycles speeding up in the era of AI, developers need to move fast without losing visibility in production. Get 4 resources covering everything from catching flaky tests and pipeline bottlenecks to instrumenting LLM calls and controlling rollouts before regressions reach users.
You’ll learn how to:
Track every CI pipeline run and cut test suite instability slowing your AI delivery cycles.
Catch LLM quality, latency, and cost issues before they surface in production.
Measure and improve release confidence as AI drives higher commit volume across your team.
Grab’s data engineering team had a problem that looks familiar to anyone who’s maintained shared infrastructure. Their best engineers were spending two full days every week answering quick questions from colleagues.
For reference, Grab is a super-app across Southeast Asia handling rides, food delivery, payments, and more. All of that activity generates enormous amounts of data, and the Analytics Data Warehouse (ADW) team is responsible for organizing and serving it to the rest of the company.
This team manages over 15,000 tables that power roughly half of all queries in Grab’s data lake, and about 1,000 people across the company query those tables every month. Analysts, product managers, and other engineers all depend on the ADW team’s tables to do their jobs.
That made the ADW team the librarians of Grab’s data, but also the help desk. The questions were quick to ask, such as “Why does this ID look like gibberish?” or “Can you add a column to this table?”
However, each answer required a fragmented journey through data catalogs, manual lineage tracing, SQL validation, and log diving. So they built a multi-agent AI system to automate the investigation process. The system worked great in demos. Then they shipped it to production, and six things broke.
But before we get to what broke and how the team handled things, let us understand what they built.
Disclaimer: This post is based on publicly shared details from the Grab Engineering Team. Please comment if you notice any inaccuracies.
The Pattern Behind the Problem
The ADW team tracked the anatomy of these questions and noticed something important. While every question was different, the process of answering them was quite consistent. An engineer would search through data catalogs, trace where the data came from, validate it with SQL queries, and check pipeline logs. The questions varied, but the investigation playbook stayed the same. This consistency was a signal for a possible automation opportunity.
Their design philosophy started with a clean separation, which they describe as decoupling the brain from the hands.
The brain is the LLM doing the reasoning. The hands are specialized agents and tools that actually fetch information, run queries, and interact with systems. By separating these two concerns, they created a system that was both capable and easy to debug. When something went wrong, they could pinpoint whether the issue was in the reasoning or in a specific tool interaction.
They also made a deliberate architectural bet.
Rather than building one massive AI trained to handle every type of question, they built multiple specialized agents, each focused on a narrow domain.
See the diagram below that shows how an AI agent works:
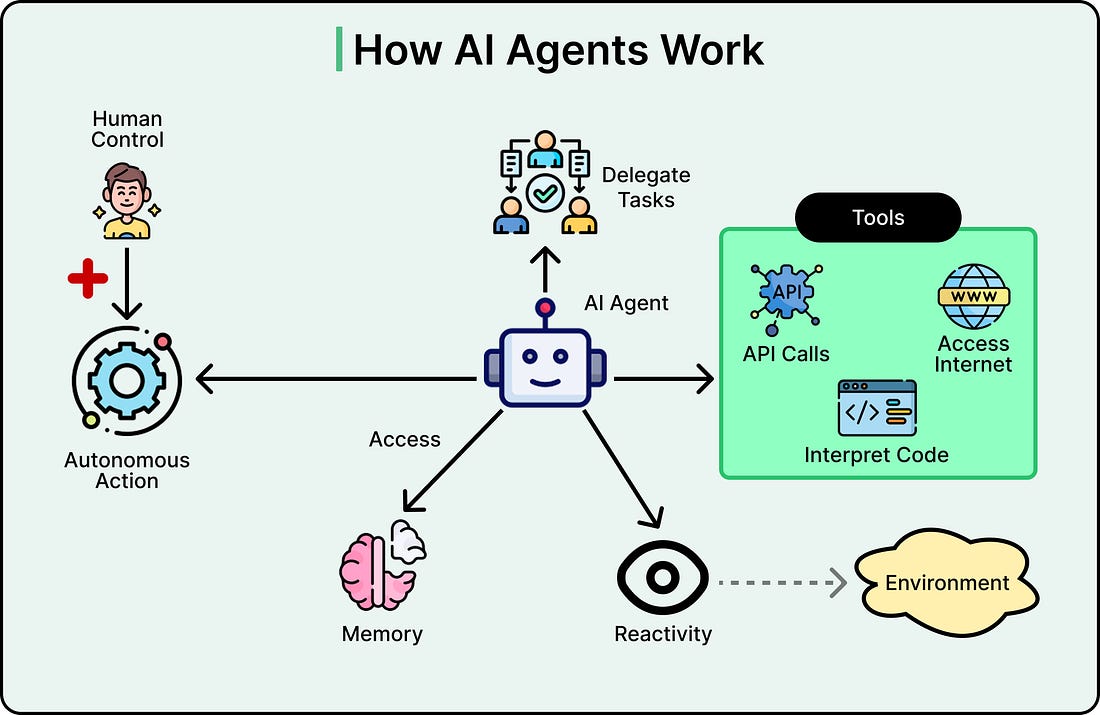 |
A single monolithic model would have been simpler to deploy with one model and one inference call, but it would also be harder to debug, and any change would risk affecting everything. On the other hand, specialized agents are modular. You can improve one without touching the others, add new ones without rewriting the system, and assign clear responsibilities that make failures traceable. The tradeoff is coordination complexity and some added latency from sequential execution.
See the comparison below:
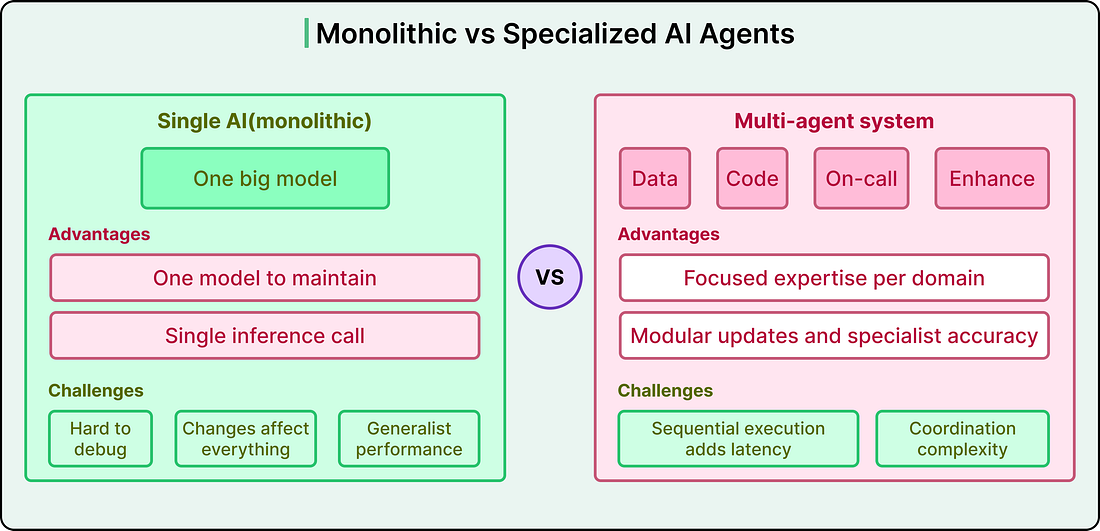 |
Grab accepted that tradeoff because maintainability and accuracy mattered more than saving a few seconds. The idea was that when you are replacing a multi-hour manual investigation, a few minutes for a precise answer is a massive improvement.
On the tech stack side, they used FastAPI to handle incoming requests and LangGraph to manage the complex stateful logic that multi-agent collaboration requires. Simple LLM calls follow a straight line from input to output, but Grab’s agents need to loop back, ask for more information, or hand off tasks to one another, and LangGraph supports that kind of cyclical workflow. Redis handles caching and real-time session needs, while PostgreSQL stores conversation history and agent metadata as persistent memory. The agents themselves pull information from three internal platforms, which are as follows:
Hubble serves as a centralized metadata and data catalog.
Genchi is a data quality observability platform that enforces data contracts.
Lighthouse tracks pipeline execution status and health.
See the diagram below: