|
Map workflows, automate E2E tests, and ship faster with QA Wolf (Sponsored)
 |
QA Wolf’s AI agent maps and tests your app’s most complex user flows.
It turns your prompts into real Playwright and Appium code that runs 12x faster and more reliably than other computer-use agents.
What sets our AI apart:
Maps 200+ test cases in minutes instead of weeks of manual planning.
Executes tests 12x faster than computer-use agents.
Runs entire suites 100% parallel with consistent results.
Produces open-source tests your team owns, with zero vendor lock-in.
This week’s system design refresher:
CPU vs GPU vs TPU (Youtube video)
Latency vs Throughput vs Bandwidth
What is Google’s TPU?
7 Permission Modes Every Claude Code User Should Know
Top AI Trends to Watch in 2026
We’re hiring at ByteByteGo
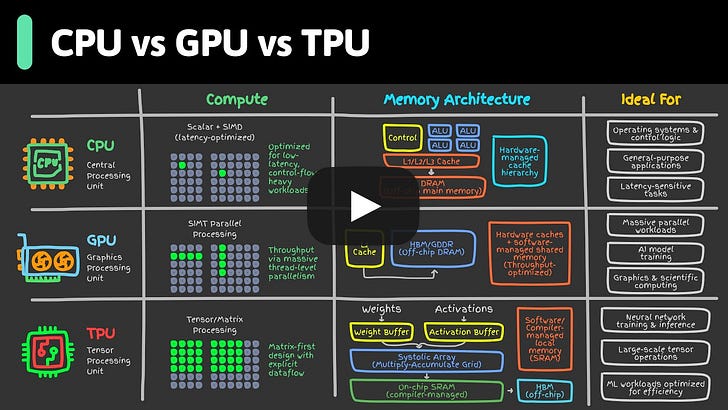
CPU vs GPU vs TPU
Latency vs Throughput vs Bandwidth
Ever wondered why your app feels slow even when the bandwidth looks fine? Latency, throughput, and bandwidth often get used interchangeably, but each one tells a different story about performance.
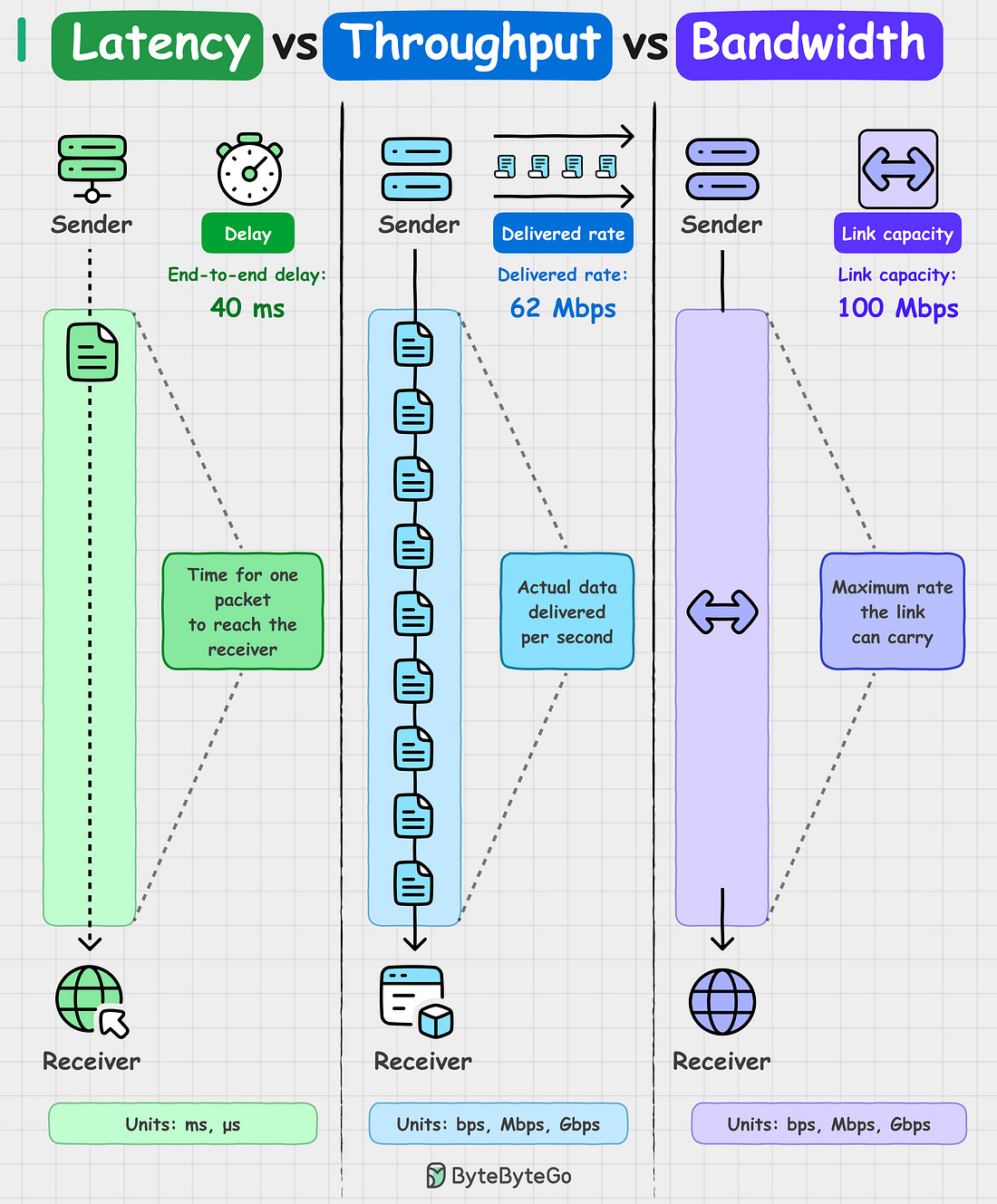 |
Latency is the delay. How long it takes for a single packet to travel from sender to receiver. If your ping shows 40 ms round-trip, that's latency.
Throughput is the actual delivery rate. How much data is successfully transferred per second. If your download shows 62 Mbps, that’s throughput.
Bandwidth is the maximum capacity of the link. For example, a 100 Mbps connection is the upper limit under ideal conditions.
Throughput is always less than bandwidth. Network congestion, packet loss, and protocol overhead all affect throughput, which is why you never actually hit the maximum bandwidth capacity in practice.
Similarly, low latency doesn't always mean high throughput. Small payloads, single connections, and tight window sizes can all keep throughput low, which is why fast responses don't guarantee you're sending a lot of data.
Another way to understand these three concepts: Bandwidth is the highway width. Throughput is the traffic flow. Latency is how long it takes a car to go from A to B.
All three matter, but they solve different problems.
Over to you: How do you measure these metrics in a way that actually predicts when things will break?
What is Google’s TPU?
A TPU (Tensor Processing Unit) is Google’s custom AI chip, designed from scratch for the giant matrix multiplications that modern models live on. GPUs were built for graphics first.
 |
TPUs were built for deep learning from day one.
At Cloud Next ’26, Google unveiled its 8th generation, and for the first time it ships in two flavors. TPU 8t is built for training, where raw throughput wins. TPU 8i is built for inference, where latency and chip-to-chip speed matter most.
Both still share the same Axion CPUs, liquid cooling, and software stack, so code written for one runs on the other.